
Многопоточность в программировании является важным механизмом в наше время. Поэтому я решил посвятить несколько статей этой теме.
В семействах ОС Windows - каждая программа запускает один процесс выполнения, в котором находится как минимум один поток (нить). В процессе может находиться множество потоков, между которыми делится процессорное время. Один процесс не может напрямую обратиться к памяти другого процесса, а потоки же разделяют одно адресное пространство одного процесса. То есть в Windows - процесс это совокупность потоков.
В Linux же немного по-другому. Сущность процесса такая же, как и в Windows - это исполняемая программа со своими данными. Но вот поток в Linux является отдельным процессом (можно встретить название как "легковесный процесс", LWP). Различие такое же - процесс отдельная программа со своей памятью, не может напрямую обратиться к памяти другого процесса, а вот поток, хоть и отдельный процесс, имеет доступ к памяти процесса-родителя [2]. LWP процессы создаются с помощью системного вызова clone() с указанием определенных флагов.
Но также имеется такая вещь, которая называется "POSIX Threads" - библиотечка стандарта POSIX, которая организует потоки (они же нити) внутри процесса. Т.е тут уже распараллеливание происходит в рамках одного процесса.
И тут встает вопрос различия терминов "поток", "процесс", "нить" и т.д. Проблема в том, что в англоязычной литературе данные термины определяются однозначно, у нас же с нашим великим и могучим имеются противоречия, что может привести к дикому диссонансу.
Но это все в общих чертах, для более точной информации следует обратиться к соответствующей литературе, либо к официальной документации, можно почитать man'ы. В конце статьи я приведу несколько полезных ссылок на ресурсы, где более подробно расписано как все работает, а пока займемся практикой.
Я рассмотрю два варианта "распараллеливания" программы - создания потока/нити с помощью функций из pthread.h (POSIX Threads), либо создание отдельного процесса с помощью функции fork().
Сегодня рассмотрим потоки из библиотеки pthread.
Шаблон кода для работы с потоками выглядит следующим образом:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
#include <pthread.h> //потоковая функция void* threadFunc(void* thread_data){ //завершаем поток pthread_exit(0); } int main(){ //какие то данные для потока (для примера) void* thread_data = NULL; //создаем идентификатор потока pthread_t thread; //создаем поток по идентификатору thread и функции потока threadFunc //и передаем потоку указатель на данные thread_data pthread_create(&thread, NULL, threadFunc, thread_data); //ждем завершения потока pthread_join(thread, NULL); return 0; } |
Как видно из кода, сущность потока воплощена в функции, в данном случае, threadFunc. Имя такой функции может быть произвольным, а вот возвращаемый тип и тип входного аргумента должны быть строго void*. Данная функция будет выполняться в отдельном потоке исполнения, поэтому необходимо с особой осторожностью подходить к реализации данной функции из-за доступа к одной и той же памяти родительского процесса многими потоками. Завершение достигается несколькими вариантами: поток достиг точки завершения (return, pthread_exit(0)), либо поток был завершен извне.
Создание потока происходит с помощью функции pthread_create(pthread_t *tid, const pthread_attr_t *attr, void*(*function)(void*), void* arg), где: tid - идентификатор потока, attr - параметры потока (NULL - атрибуты по умолчанию, подробности в man), function - указатель на потоковую функцию, в нашем случае threadFunc и arg - указатель на передаваемые данные в поток.
Функция pthread_join ожидает завершения потока thread. Второй параметр этой функции - результат, возвращаемый потоком.
Попробуем по этому шаблону написать программу, которая выполняет что-то полезное. Например, попытаемся сложить две матрицы и сохранить результат в третьей результирующей матрице. Для решения данной задачи уже необходимо подумать о правильном распределении данных между потоками. Я реализовал простой алгоритм - сколько строк в матрице, столько потоков. Каждый поток складывает элементы строки первой матрицы с элементами строки второй матрицы и сохраняет результат в строку третей матрицы. Получается, что каждый поток работает ровно со своими данными и таким образом исключается доступ одного потока к данным другого потока. Пример программы с использованием потоков pthread выгляди следующим образом:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 |
#include <pthread.h> #include <stdlib.h> #include <mcheck.h> #include <stdio.h> //размеры матриц #define N 5 #define M 5 //специальная структура для данных потока typedef struct{ int rowN; //номер обрабатываемой строки int rowSize; //размер строки //указатели на матрицы int** array1; int** array2; int** resArr; } pthrData; void* threadFunc(void* thread_data){ //получаем структуру с данными pthrData *data = (pthrData*) thread_data; //складываем элементы строк матриц и сохраняем результат for(int i = 0; i < data->rowSize; i++) data->resArr[data->rowN][i] = data->array1[data->rowN][i] + data->array2[data->rowN][i]; return NULL; } int main(){ //выделяем память под двумерные массивы int** matrix1 = (int**) malloc(N * sizeof(int*)); int** matrix2 = (int**) malloc(N * sizeof(int*)); int** resultMatrix = (int**) malloc(N * sizeof(int*)); //выделяем память под элементы матриц for(int i = 0; i < M; i++){ matrix1[i] = (int*) malloc(M * sizeof(int)); matrix2[i] = (int*) malloc(M * sizeof(int)); resultMatrix[i] = (int*) malloc(M * sizeof(int)); } //инициализируем начальными значениями for(int i = 0; i < N; i++){ for(int j = 0; j < M; j++){ matrix1[i][j] = i; matrix2[i][j] = j; resultMatrix[i][j] = 0; } } //выделяем память под массив идентификаторов потоков pthread_t* threads = (pthread_t*) malloc(N * sizeof(pthread_t)); //сколько потоков - столько и структур с потоковых данных pthrData* threadData = (pthrData*) malloc(N * sizeof(pthrData)); //инициализируем структуры потоков for(int i = 0; i < N; i++){ threadData[i].rowN = i; threadData[i].rowSize = M; threadData[i].array1 = matrix1; threadData[i].array2 = matrix2; threadData[i].resArr = resultMatrix; //запускаем поток pthread_create(&(threads[i]), NULL, threadFunc, &threadData[i]); } //ожидаем выполнение всех потоков for(int i = 0; i < N; i++) pthread_join(threads[i], NULL); //освобождаем память free(threads); free(threadData); for(int i = 0; i < N; i++){ free(matrix1[i]); free(matrix2[i]); free(resultMatrix[i]); } free(matrix1); free(matrix2); free(resultMatrix); return 0; } |
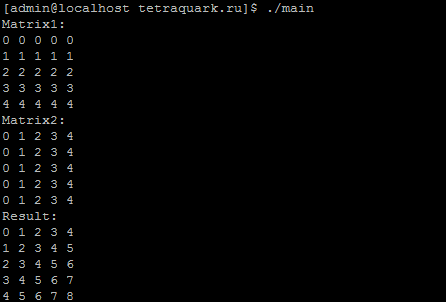
Результат выполнения в ОС CentOS 7 с выводом в консоль выгляди следующим образом:
Для компиляции программы с использованием pthread, линковщику следует указать флаг -lpthread (или подключить библиотеку pthread в IDE). Команда для компиляции в gcc будет выглядеть примерно так:
gcc -std=c99 main.c -o main.out -lpthread
Собственно, это все, что я хотел сообщить. Приведу еще пару полезных ссылок на ресурсы для более подробного изучения. В следующих статьях будут рассмотрены механизмы мьютекосв для данных потоков и примеры работы с функцией fork().
Полезные материалы:
variant2
Товарищи, ну зачем вы пишите такие примеры? Почему нельзя сделать кучу маленьких примеров в 10 строк вместо одного большого на 8 десятков? Для кого вы это пишите? Новичкам вы только вредите, а профессионалам это и даром не надь.
Человек хочет узнать, что такое потоки и как их юзать, а в примере какие-то структуры, массивы, циклы…
Это только отвлекает внимание от сути.
Ну представьте, сидите вы на форуме, приходит новичок с вопросом и вываливает свой код на сотню строк. Вы же первые его закидаете тухлыми помидорами и пошлете куда по-дальше, потому как разбираться в коде, где большая часть его к сути вопроса отношения не имеет — занятие неблагодарное.
Во-первых, в статье есть пример простейшего кода для создания потока на 20 строк с комментариями и пояснениями в тексте.
Во-вторых, вторая программа нужна для отражение примера кода, на основе которого можно понять базовые принципы работы с многопоточными программами и как это все правильно «юзать» с данными. Это простой пример, с которыми работают студенты начальных курсов университетов и отлично с этим справляются.
В-третьих, если, как Вы говорите, новичок не знает что такое циклы, массивы и структуры, но сразу начинает изучать потоки, то тут явно что-то не так, для такого уровня не предназначена эта статья. Это основы, без которых не получится писать многопоточные программы и, пожалуй, прежде стоит хорошо изучать основы языка.
К сожалению, ничего не поделать и написать хороший пример программы с posix-потоками на 10 строк кода для языка С вряд ли получится.
Правильно замечено в статье что каждый поток должен работать со своими данными, в этом и есть смысл потоков
Отличный второй пример, помог быстро разобраться с концепцией многопоточности. Спасибо!